
Study: Data & AI
Data Explosion
We start with a very well-known fact that data storage costs have decreased exponentially over the last 70 years:
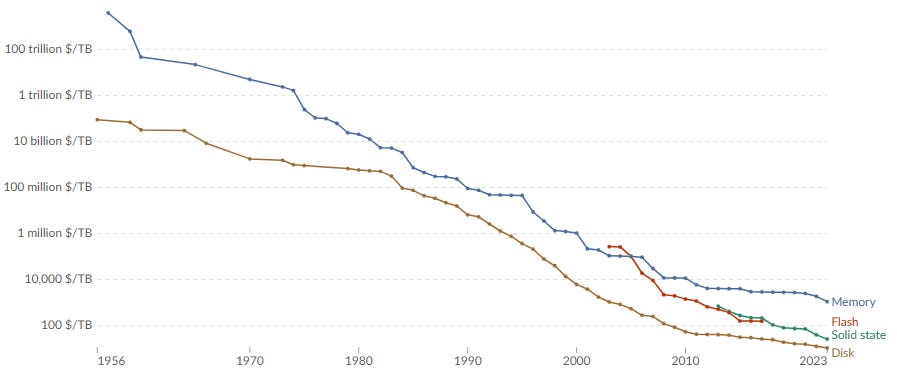
This trend of the data explosion is driven by lower hardware costs and by business models that made these hardware easy to access. Because of that, the world started to create, log, save and use more data than before.
There are some business models that won in the last decade from this downstream data explosion:
Content, advertising, social ecosystems (eg. Meta, Alphabet)
E-commerce, delivery, logistics ecosystems (eg. Amazon)
Infrastructure required to support #1 and #2 (eg. Smartphones, semiconductors)
Developer tools to build #3 (eg. AWS)
Consider advertising, it is still the largest economic engine of the Internet. Meta, YouTube, Reddit, Instagram etc. all rely on this value creation loop:
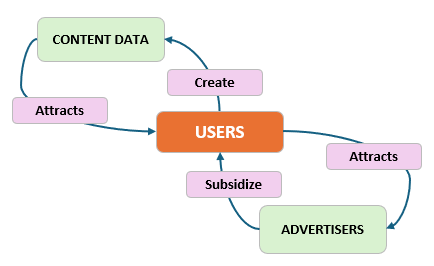
This flywheel begins with companies being able to offer users cheap storage for data. Thereby attracting more users, who attracts advertisers, who subsidize the platform. The cycle continues. But none of this is possible without cheap, plentiful data.
Another ecosystem is delivery and logistics. The iconic example is Amazon, which has this flywheel of data loop:
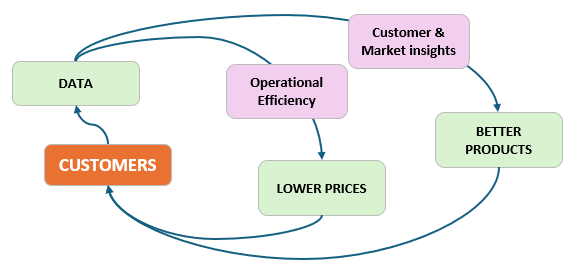
The above flywheel requires knowledge of customer locations, purchase and travel habits, inventories and route geographies, drivers availability… all these are only possible with cheap, plentiful data.
These two ecosystems are not just powered by data; they generate new data on their own. This self enriching loop is a very powerful value creation mechanism for both consumers and the business itself.
Complementary Inputs
Obviously data is an important input into these ecosystems, but there’s another input which is the opposite side of the same coin. That’s software!
The software used to optimize this loop is useless without the data to apply. And the data is worthless without software to interpret and act on it.
These two are complementary inputs: both must exist to generate the desired output. An immediate consequence is that if the price of one input falls, then the price of the other will increase.
To give an analogy, imagine that you’re a tailor. To sew clothes, you need needles and fabric, and the only limitation is the quantity of each of those inputs. If the price of needles falls due to a new manufacturing technology, then to sew more clothes, you would use the savings from needles to buy more fabric. If every tailor does this, the price of fabric will rise. Tailors and consumers are both better off with a higher total quantity of clothing produced, but the relative value of needles and fabric has changed.
In the last decade, the quantity of data has been exploding and the price has been decreasing. Software then became the relatively scarce input, so it’s price has increased. We can see this manifesting in the high salaries of software engineers and the high pricing power of software companies.
Marc Andreessen wrote in 2011 that “software ate the world”, but we want to add “with the huge help from cheap, plentiful data”.
Enter Artificial Intelligence (AI)
Jensen Huang said something in CES 2025 that caught our attention which was the main motivator for writing this post. We paraphrase:
Software sits on a stack above data. Everyone uses software. AI is the new stack that sits on top of software – that is why it’s a growth industry.
Data explosion has run its course, today we are looking at compute explosion.
The most immediate observation is the complementary nature of compute and data. A compute explosion actually makes data more valuable. Companies that already own data will benefit, but simply having high volumes of data is not good enough. The value capture is with companies that own unique data sets, they will be able to monetize those data assets more effectively. A good example is BloombergGPT trained on copious amount of high quality financial data which not many competitors have.
Some companies will find themselves owning latent data sets which initially have no value but now can be monetized. For example, Reddit has a lot of human generated content cleaned by moderation and upvoting system. Now they can charge money for it.
Even a small custom data set can hold a lot of value by layering the AI stack on top of proprietary data.
In short, data under the AI world is not simply about quantity, instead higher quality data drives greater value.
The very best data assets plugged into AI create use cases that are the most valuable. There are opportunities for tools that are specifically designed to take advantage of this innovation. The entire data stack needs to be refined such that AI models become the consumers and producers of data.
Another consequence of AI is that generative models don’t just consume data, they also produce data. Therefore, companies that own high quality data and have these tools, will likely have a value model similar to the prior data flywheel:
Tools to build new data assets for AI
Tools to connect existing data assets to AI infrastructure
Tools to extract latent data sets using AI
Tools to monetize data assets
Currently when we want to improve customer experiences, we first improve the software process which involves a human in the loop. However, in the future, when AI models sit on top of the software stack, it is possible to have an AI agent improving the software process which ultimately improves the customer experience without human intervention.
This presents a huge potential for productivity boost.
New Productivity Flywheel
The new value generating flywheel probably looks like this:
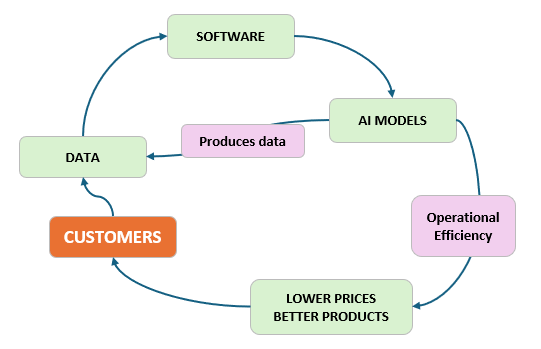
It doesn’t look much different from the Amazon flywheel, but we argue that it’s easier to accelerate this new flywheel:
Previously, human workers will be at the end user of software, now AI models likely function faster than humans to extract customer insights from data.
AI agents can produce or clean up data, resulting in a higher quality more relevant data set. This improves efficient data extraction.
At scale the marginal AI output cost is very low which should drive cost savings.
So where are the new areas of scarcity?
Hardware that powers compute and data is one area, this is already well-known with companies like NVIDIA and TSMC. Another area is energy; training and inferencing AI models require huge amounts of energy.
A more contentious one is artificial scarcity where corporations seek to artificially constrain data and computation to extract consumer surplus.