
Study: CPU in AI Processes
Preface
These notes are not from us. It’s a compilation of conversations offline with people familiar with the topic, edited for reading.
Intro
For the last 2 years, the topic of AI compute was centered around GPUs. It is still true today, but there are developments in agentic AI (agents) that shifts the inference portion away from GPUs and into CPUs.
The reason is that agentic AI systems work on multiple processes like tool calls, API requests, memory lookups, orchestration logic, all of which are handled by the CPU. In this environment, CPU cores play a big role — more cores means more tasks, and memory hierarchy determine GPU utilization. These factors contribute to overall throughput and total cost of ownership of a compute rack.
Due to the way AI agents work, the demand will shift the CPU-to-GPU ratio in a compute rack towards CPUs. We can take the signals from Nvidia launching Vera CPU on 1 June 2026, selling it as standalone platform for agentic processing.
For those technically inclined, you can read this paper in November 2025 which estimated that tool processing on CPUs accounting for 50% to 90% of total latency in agentic workloads.
Inference vs. Agentic Workloads
The LLM (large language model) workflow that we’re all familiar with looks like that:
Human types a request.
CPU tokenize text (into numerical tokens) for the model to process.
GPU takes the tokens and run the model for inference.
CPU de-tokenize into text and produce the reply.
Human reads & processes the info, and acts on it.
This loop is called “pure inference”. It’s slow since there is a human processing the info. Notice that the CPU’s role is limited to getting the request to the GPU and fetching the output to the user.
All the compute happens on GPU, that’s why the GPU has dominated AI infrastructure, as the CPU is not the bottleneck.
However, in agentic workloads, the human is not in the loop. A person triggers a request, then agents read, plan, call for tools, and produces the result. The difference is that there can be many sub-agents per person, all running this loop simultaneously. So the faster this loop completes, the quicker agents finish their tasks.
More agents means that tasks must be performed in parallel, leading to the need for “orchestration of agents”, which all happens on the CPU.
In an agentic workload, the CPU performance dictates GPU utilization rate:
Human types a request.
CPU tokenizes it and generates an execution plan.
Multiple sub-agents run in parallel to carry out the plan. Each using different tools and having different runtime.
CPU manages the relationship between sub-agents. Some of them are independent, others are dependent on order of completion.
Sub-agents passes the tokens to GPU for calculation.
CPU de-tokenize output, collates and produce output.
Notice a few requirements here:
CPU with high clock frequency can monitor tokens at low latency. This means it can pass tokens between sub-agents quickly.
CPU with high core count allow for many sub-agents to run parallel.
Low latency access to memory is important for long context windows.
Reasoning vs Action Oriented Workloads
The type of workload, whether reasoning or action, affects the CPU/GPU ratio. For sake of simplicity, we assume matrix operations are only handled by GPUs. So we don’t discuss features like Intel’s Advanced Matrix eXtention (AMX) where inference can occur on CPUs.
We can consider these 9 metrics below to show the relative reliance on the CPU:
(1) Per-core performance and clock speed
CPU needs to make orchestration decisions quickly to keep the GPU busy. Clock speed determines efficiency.
(2) Core count
Higher core counts means more agents can run in parallel. Single agents can also use multiple cores.
(3) CPU-xPU interconnect
xPU means whatever “x” computing architecture you’re using (GPU, TPU, NPU…). The better the interconnect, the faster data can be transferred.
(4) CPU memory
Higher memory bandwidth allows for larger context windows.
(5) Cache design and size
L3 cache is a high-speed memory bank located on the CPU. It acts as a staging area between the CPU cores and the slower main system RAM. More L3 cache means lower memory latency.
(6) Performance per watt
The standard measure of unit economics; how much energy is required for a given compute task.
(7) PCIe generation and lane count
Agents can do many actions, like API calls, read storage, go online… PCIe (Peripheral Component Interconnect Express) generations determine the raw speed of the data, while lane counts (the number of physical data pathways) dictate how much total data can travel at once.
(8) Instruction Set Architecture (ISA)
x86 or ARM determines what support exists for tool calls, and what ecosystem you use. For example:
Grace (ARM) + Nvidia GPU
x86 + Google TPU
(9) Non Uniform Memory Access (NUMA) domains
Modern server CPUs are composed of multiple chiplets to accommodate many cores. Depending on the interconnect technology between chiplets and physical layout, each CPU can have a non-uniform access latency to memory. This implies agents running on different cores can see different memory performance.
Now, we can compare a reasoning-oriented against action-oriented workflow across these 9 metrics.
Reasoning-Oriented
Consider this reasoning-oriented task:
Produce a comprehensive analysis of the memory chips market based on a large collection of research reports.
The agent plans a few research areas and assigns to sub-agents. Then, the sub-agents run inference loops, generating reasoning tokens, reads uploaded documents, goes online to search… Once all sub-agents finish, the CPU de-tokenize and produce output.
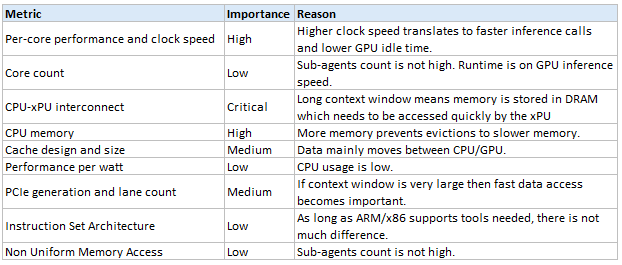
Nvidia’s Vera CPU is well suited for reasoning-oriented workloads.
CPU-xPU interconnect uses NVLink-C2C at 1.8TB/s bidirectional. Coherent memory sharing lets their Rubin GPUs read directly from Vera CPUs memory. Applications can treat LPDDR5X and HBM4 as a single coherent pool, reducing data movement overhead and enabling techniques such as KV-cache offload and efficient multi-model execution.
CPU memory is 1.5TB LPDDR5X across 8 SOCAMM (Small Outline Compression Attached Memory Modules) up to 1.2TB/s of bandwidth at low power.
Action-Oriented
Suppose you run a company and deploy agents for logistics:
There are thousands of customer requests.
Each customer has records from a database.
Logistics data comes from third-party database.
Agents need to generate an update for your customers and send an email to them.
This situation likely employs hundreds of agents running in parallel, with the GPU doing small inference. Most of the time would be spent on CPU orchestration.
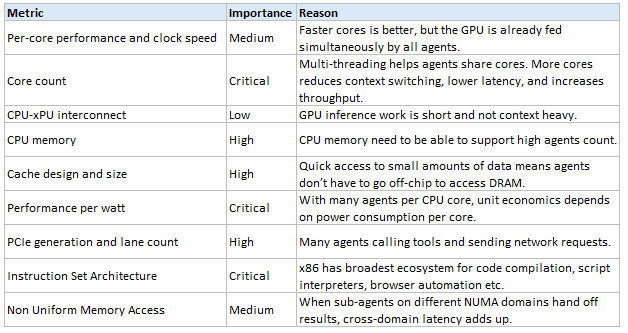
We can see that CPU-related metrics matter more when it comes to action-oriented workloads. In this case, AMD’s Venice Dense CPU is suitable:
High instructions per clock and 4MB L3 cache per core × 32 cores per CCD × 8 CCDs = 1 GB L3 cache. "Core per CCD" refers to how AMD organizes processor cores into individual, modular building blocks called CCDs (Core Complex Dies).
256 Zen6c cores, 512 threads with SMT (Simultaneous Multithreading). Many cores for many agents.
x86 architecture.
AMD’s multi-chiplet architecture (which links multiple compute chiplets to a central I/O die) means that cores are separated into distinct Non-Uniform Memory Access (NUMA) domain. If a core needs to pull data in a memory bank on a different chiplet, it must route through the central I/O die, increasing latency.